Tutorial¶
For Domain Adaptation on Computer Vision Tasks
Authors: Junguang Jiang
In this tutorial, you will learn how to use domain adaptation in image classification. If you want to know more about domain adaptation or transfer learning, please refer to A Survey on Transfer Learning or DANN
Load Data¶
DALIB provides visual datasets commonly used in domain adatation research, including Office-31, Office-Home, VisDA-2017 and so on.
# Data augmentation and normalization for training
# Just normalization for validation
import torchvision.transforms as transforms
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
val_tranform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
from torch.utils.data import DataLoader
from dalib.vision.datasets import Office31
data_dir = "data/office31"
source = "A" # source domain: amazon
target = "W" # target domain: webcam
batch_size = 32
# download data automatically from the internet into data_dir
train_source_dataset = Office31(root=data_dir, task=source, download=True, transform=train_transform)
train_source_loader = DataLoader(train_source_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
train_target_dataset = Office31(root=data_dir, task=target, download=True, transform=train_transform)
train_target_loader = DataLoader(train_target_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
val_dataset = Office31(root=data_dir, task=target, download=True, transform=val_tranform)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
If you want to implement your own datasets, you can inherit class from torchvision.datasets.VisionDataset or dalib.vision.datasets.ImageList. For instance, if your task is partial domain adaptation on Office-31, you can construct datasets as follows.
from dalib.vision.datasets import ImageList
class Office31PDA(ImageList):
"""Datasets for PDA (partial domain adaptation) on Office-31
Parameters:
- **root** (str): Root directory of dataset
- **task** (str): The task (domain) to create dataset. Choices include ``'A'``: amazon, \
``'D'``: dslr, ``'W'``: webcam, ``'AP'``: partial amazon, ``'DP'``: partial dslr \
and ``'WP'``: partial webcam.
"""
image_list = {
"A": "amazon.txt",
"D": "dslr.txt",
"W": "webcam.txt",
"AP": "amazon_partial.txt",
"DP": "dslr_partial.txt",
"WP": "webcam_partial.txt",
}
def __init__(self, root, task, **kwargs):
assert task in self.image_list
data_list_file = os.path.join(root, self.image_list[task])
super(Office31PDA, self).__init__(root, num_classes=31, data_list_file=data_list_file, **kwargs)
Note
- Your need to put image list file under root before using Office31PDA.
- “amazon.txt” list the images of all categories in amazon domain, and “amazon_partial.txt” list the images of some categories in amazon domain.
You can refer to dalib.vision.datasets.ImageList for the detailed format of image list file.
After constructing Office31PDA you can use the same data loading code as described above.
Parepare models and adaptation algorithms¶
We will use DANN as an instance. You can find the usage of other adaptation algorithms in DALIB APIs or examples on github.
DANN introduces a minimax game into domain adaptation, where a domain discriminator attempts to distinguish the source from the target, while a feature extractor tries to fool the domain discriminator.
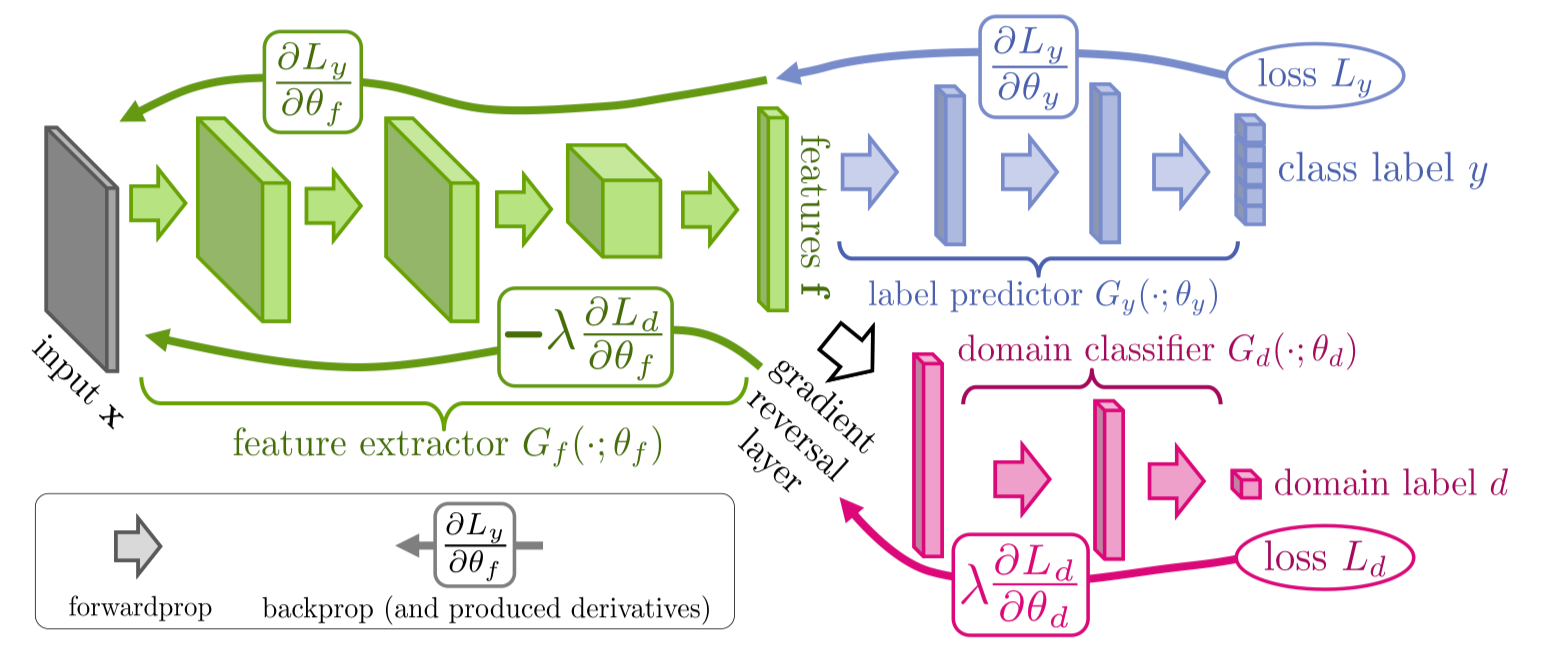
To prepare models for training, you need to
- load a pretrained model without final fully connected layer.
- construct a classifier and a domain discriminator.
- pass the domain discriminator to the DomainAdversarialLoss.
# load pretrained backbone
from dalib.vision.models.resnet import resnet50
backbone = resnet50(pretrained=True)
from dalib.modules.domain_discriminator import DomainDiscriminator
from dalib.adaptation.dann import DomainAdversarialLoss, ImageClassifier
# classifier has a backbone (pretrained resnet50), a bottleneck layer
# and a head layer (nn.Linear)
classifier = ImageClassifier(backbone, train_source_dataset.num_classes).cuda()
# domain discriminator is a 3-layer fully connected networks, which distinguish
# whether the input features come from the source domain or the target domain
domain_discriminator = DomainDiscriminator(in_feature=classifier.features_dim, hidden_size=1024).cuda()
# define loss function
dann_loss = DomainAdversarialLoss(domain_discriminator).cuda()
# define optimizer and lr scheduler
from tools.lr_scheduler import StepwiseLR
optimizer = SGD(classifier.get_parameters() + domain_discriminator.get_parameters(),
lr=0.01, momentum=0.9, weight_decay=1e-3, nesterov=True)
# learning rate will drop from 0.01 each step
lr_scheduler = StepwiseLR(optimizer, init_lr=0.01, gamma=0.001, decay_rate=0.75)
Note
We will use some functions from tools, such as StepwiseLR and ForeverDataIterator for clearer code. We will only explain their functionality. Please refer to Tutorial for runnable code.
Training the model¶
Now, let’s write a general process to train a model.
# start training
best_acc1 = 0.
for epoch in range(args.epochs):
# train for one epoch
train(train_source_iter, train_target_iter, classifier, dann_loss, optimizer, lr_scheduler)
# evaluate on validation set
acc1 = validate(val_loader, classifier)
# remember best acc@1
best_acc1 = max(acc1, best_acc1)
During training, we explicitly set 1 epochs equal to 500 steps.
import torch.nn.functional as F
def train(train_source_iter, train_target_iter, model, dann_loss, optimizer, scheduler):
# switch to train mode
model.train()
dann_loss.train()
# train_source_iter and train_target_iter is data iterator that will never stop producing data
T = 500
for i in range(T):
scheduler.step()
# data from source domain
x_s, labels_s = next(train_source_iter)
# data from target domain
x_t, _ = next(train_target_iter)
x_s = x_s.cuda()
x_t = x_t.cuda()
labels_s = labels_s.cuda()
# compute output
y_s, f_s = model(x_s)
# cross entropy loss on source domain
cls_loss = F.cross_entropy(y_s, labels_s)
_, f_t = model(x_t)
# domain adversarial loss
transfer_loss = dann_loss(f_s, f_t)
loss = cls_loss + transfer_loss
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
The evaluation code is similar as in supervised learning.
from tools.util import AverageMeter, accuracy
def validate(val_loader, model):
top1 = AverageMeter('Acc@1', ':6.2f')
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (images, target) in enumerate(val_loader):
images = images.cuda()
target = target.cuda()
# compute output
output, _ = model(images)
# measure accuracy and record loss
acc1, = accuracy(output, target, topk=(1, ))
top1.update(acc1[0], images.size(0))
print(' * Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}'
.format(top1=top1, top5=top5))
return top1.avg
Visualizing the results¶
After the training is finished, we can visualize the representations of task A → W by t-SNE.
# get features from source and target domain
classifier.load_state_dict(best_model)
classifier.eval()
features, domains = [], []
source_val_dataset = dataset(root=data_dir, task=source, download=True, transform=val_tranform)
source_val_loader = DataLoader(source_val_dataset, batch_size=batch_size, shuffle=False)
with torch.no_grad():
for loader in [source_val_loader, val_loader]:
for i, (images, target) in enumerate(loader):
images = images.cuda()
target = target.cuda()
# compute output
_, f = classifier(images)
features.extend(f.cpu().numpy().tolist())
features = np.array(features)
# map features to 2-d using TSNE
X_tsne = TSNE(n_components=2, random_state=33).fit_transform(features)
# domain labels, 1 represents source while 0 represents target
domains = np.concatenate((np.ones(len(source_val_dataset)), np.zeros(len(val_dataset))))
# visualize using matplotlib
import matplotlib.pyplot as plt
import matplotlib.colors as col
plt.figure(figsize=(10, 10))
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=domains, cmap=col.ListedColormap(["r", "b"]), s=2)
plt.show()
Figures below shows the T-SNE visualization results of A → W on ResNet50 (source only) and DANN.
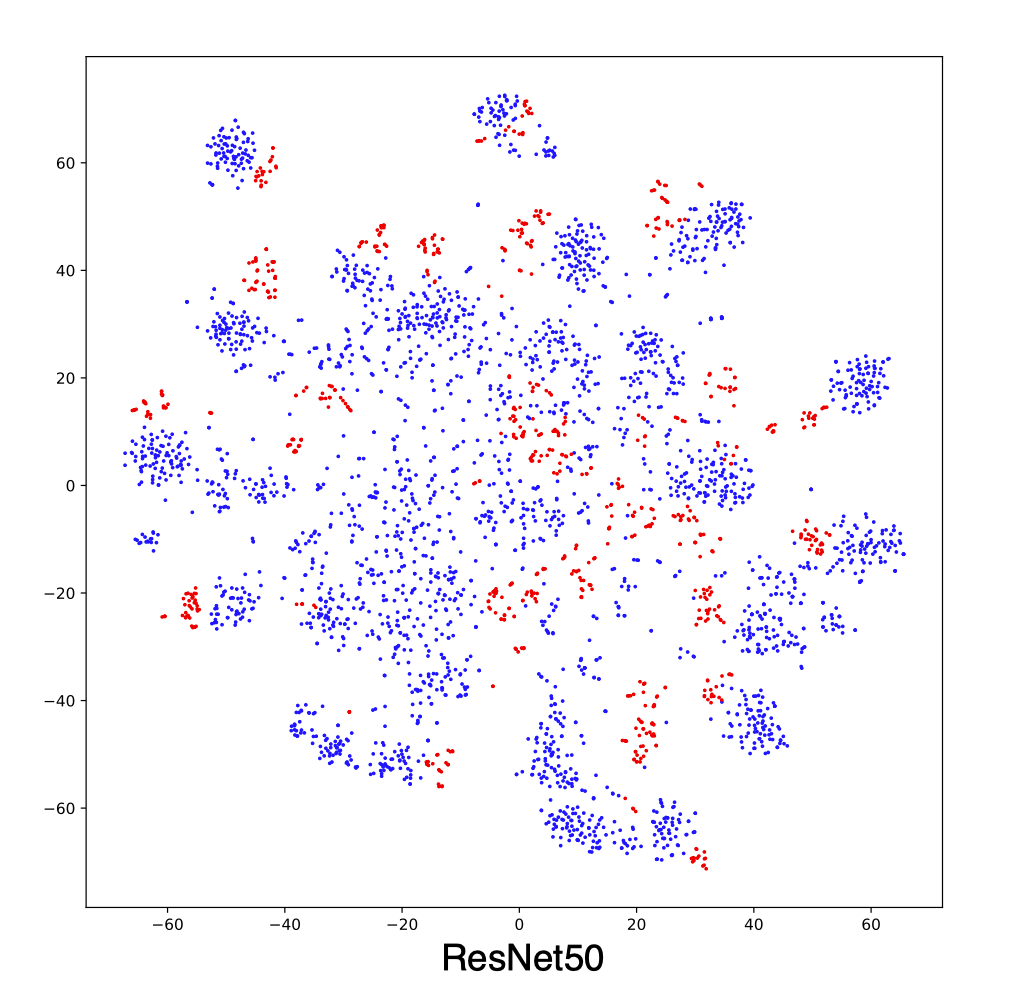
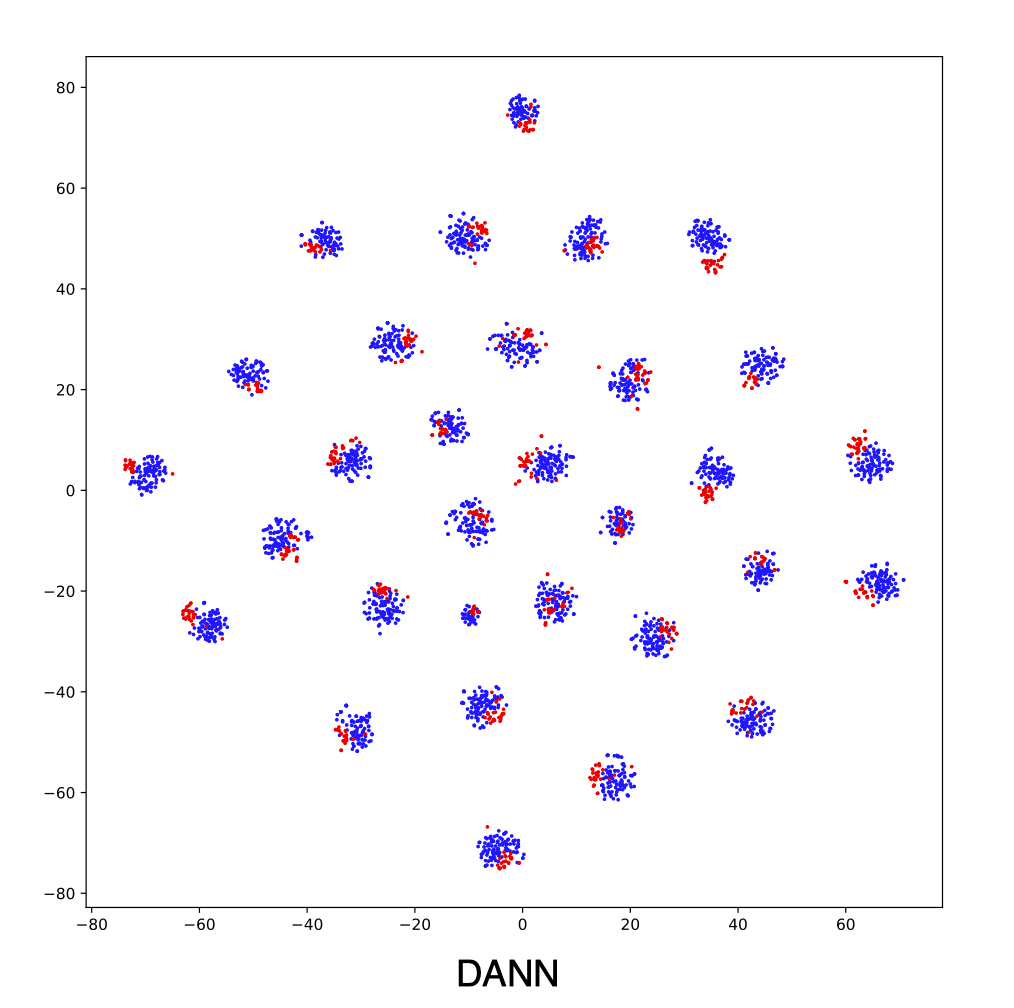
The source and target are not aligned well with ResNet (source only), better aligned with DANN. For better alignment, you are encouraged to replace DANN with CDAN.
Runnable code can be found in Tutorial. The following script is expected to achieve ~86% accuracy.
python examples/tutorials.py data/office31 -d Office31 -s A -t W -a resnet50 --epochs 10 --seed 0